[拼音]:chouyang diaocha
[外文]:sampling survey
一种统计学方法,也是数理统计学的一个分支。它通过从总体中抽取一部分个体进行调查,借以获得对整个总体的特征的了解。抽样调查主要用于社会、经济、农业和人口等领域;被调查的总体通常是有限的,它的个体可以辨别。
最简单的抽样设计是无放回随机抽样,还有分层抽样、定额抽样、系统抽样、分群抽样、多级抽样等复杂的方法。抽样调查的理论问题,可归入有限总体推断理论的研究之内,主要是讨论各种不同的抽样设计的相对效率,以及与之相应的种种估计方法(如比率估计、回归估计)的优良性。近二三十年来,由于应用上的需要,随着有限总体推断理论研究的开展,抽样调查已逐渐成为数理统计学的一个活跃的分支。
出于对费用和时间的考虑,人们早已认识到需要在调查中进行抽查而不是普查。但对抽查结果的可靠性一开始是有怀疑的。第二次世界大战期间,各交战国为适应急剧变化的战局,亟需及时而有效地收集情报,除抽样调查外别无他法,这就促进了对抽样调查的理论和方法的研究。战后不久,出现了这方面的专著,F.耶茨受联合国统计抽样专业委员会的委托,为协助1950年世界农业和世界人口调查而写的《人口调查与一般调查的抽样方法》就是其中之一。50年代后,世界各国已逐渐把抽样调查作为一种重要的调查方法。这是因为,普查的工作量太大,往往为人力财力时间所不允许,在实施过程中易出现人为的误差错;经验表明,有时一个精心设计的抽样方案,其实施效果甚至可以胜过普查。
在抽样调查中,有时不能以自然个体为单位,而要按实际需要和使用方便把这些自然个体划分为若干单元,抽样时把每个单元看作一个个体,称为抽样单元。例如人口调查中的个人、家庭;又如在地图上划分方格,每格代表一个抽样单元,格的大小也可不同。构成总体的全部抽样单元的一个总的描述叫抽样框。载有总体中每个抽样单元的一本名册、一幅地图或者一份档案,就是抽样框。
抽样方法分成概率抽样和判断抽样两大类:前者指每个抽样单元都依指定的概率被抽取,又称随机抽样;后者是根据调查者的判断从总体中选一些有代表性的单元进行调查。判断抽样又称典型抽样。
无放回随机抽样从N 个抽样单元组成的总体中抽取含n个单元的样本(n≤N),方法是,在抽取第一个时,让N个抽样单元中每一个以同等概率1/N被抽到,抽到的这一个不再放回到总体中去,然后在剩下的N-1个中抽出1个,每个被抽出的概率都是1/(N-1),抽到的这一个不再放回,这样下去,直到抽出n个为止。这种抽样方法叫做无放回随机抽样。它使得N个抽样单元中的任何n个都有同等的概率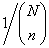 被抽到。在抽样调查中,通常把它叫做简单随机抽样,抽到的样本称为简单随机样本。但它与数理统计学中一般意义下的简单随机抽样(见样本)是有区别的,后者每个样本观测值的分布是相互独立的,而这里由于每个单元在调查后不再放回到总体中去,它们的分布就不是相互独立的了。
被抽到。在抽样调查中,通常把它叫做简单随机抽样,抽到的样本称为简单随机样本。但它与数理统计学中一般意义下的简单随机抽样(见样本)是有区别的,后者每个样本观测值的分布是相互独立的,而这里由于每个单元在调查后不再放回到总体中去,它们的分布就不是相互独立的了。
设有N个单元构成的有限总体(如某校全体新生),其某一特性Χ(如年龄)用Χ1,Χ2,…,ΧN表示,所抽得的样本用x1,x2,…,xn表示(为方便起见,将样本中的序号仍记为1,2,…,n,但不一定就是总体中的前n个单元,下同)。以Χ和塣分别记总体的总和 Χ1+Χ2+…+XN和总体均值(塣=Χ/N);以x和塣分别记样本的总和x1+x2+…+xn和样本均值(塣=x/n)。在简单随机抽样中,样本均值塣是总体均值塣的无偏估计量(见点估计),这时,总体总和Χ的估计量是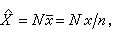 式中N/n称为放大因子,即将样本总和放大 N/n倍便得总体总和的一个合理估计。放大因子的倒数n/N,称为抽样比例。
式中N/n称为放大因子,即将样本总和放大 N/n倍便得总体总和的一个合理估计。放大因子的倒数n/N,称为抽样比例。
实际上,不少抽样调查问题,都可化为估计总体均值的问题。例如,要了解具有某种特性的单元在总体中所占的比例,只要根据第i 个单元有无此特性而分别令Χi=1或者0;这时,Χ1,Χ2,…,ΧN的平均值塣就是所要求的比例。
在抽样调查中,一个抽样方法及其相应估计方法的精度以所得的估计量的均方误差表示。均方误差就是估计量与被估计量(真值)的差的平方的数学期望。当估计量无偏时,均方误差就等于方差。按简单随机抽样方法,若用样本均值塣 估计总体均值塣,它的方差是
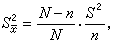
式中
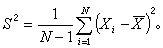
当N、n及N-n都较大时,可以用正态分布近似塣的分布,从而可以利用正态分布或 t分布(见统计量)定出总体均值塣的置信区间(见区间估计)。
分层抽样为了得到有代表性的样本,按一种或多种标志把总体划分为若干子总体;尽可能使每个子总体内的单元之间的差异比较小,而不同子总体间的差异比较大。这样,只要在每个子总体内抽少数单元就可得到代表性很强的样本。称子总体为层,这种方法叫分层抽样。例如在小麦估产调查中,将麦田分为山地、平地、洼地三类,每类就是一个子总体。
如在每一层内都用简单随机抽样的方法抽取一定数目的单元,就称为分层随机抽样,通常说的分层抽样均指分层随机抽样。如每一层的抽样数目是事先指定好的,在总体中由调查人根据他的判断进行抽样,直到每一层的抽取数与事先指定的都相符为止,这种抽样称之为定额抽样。例如,在服装调查中,将男子分为少年、成年、老年三类,规定分别抽取n1、n2、n3个,则在某一人群中抽样时,要一直抽到有n1个少年,n2个成年,n3个老年时为止。
假定总体分为L层,依次有 N1、N2、…、NL个单元,总体大小
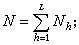
在各层中分别抽取大小为n1、n2、…、nL的简单随机样本,则样本大小
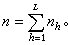
当n给定时, 如何分配n1、n2、…、nL使得对总体均值的估计量的方差为最小,这是实际应用中的一个很重要的问题。J.奈曼指出,当
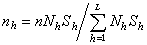
时,这个估计量的方差为最小 ,式中 S崺为第 h层的方差。这种分配方法叫奈曼分配。若各层中的单元抽查费用不同,费用函数C可写成
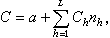
式中α为固定费用,与n的大小无关,Ch为在第h层中每抽查一个单元的费用,则对给定费用C,方差最小的样本量分配公式是
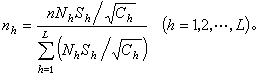 系统抽样
系统抽样
又称等距抽样或机械抽样,是指按一定方式系统地抽取样本的方法。例如,从一张名单上按一定间隔抽取样本就是一种系统抽样。其做法是:先求一个最接近于N/n的整数q,从随机数表(见伪随机数)中读一个在1与q之间的数k(叫随机起数),然后按间隔q抽取顺序号码为k,q+k,2q+k,…等单元。如编号与被调查的特性无关,则系统抽样可视同随机抽样,且更简易;如编号相近的单元有相似的特性,则系统抽样接近于分层抽样。还可以将抽样间隔q放大d(整数)倍,并从随机数表读d个不同的随机起数,对每个起数按间隔dq抽取单元。
分群抽样为节约费用和时间,抽样前按某种准则将总体分为若干群,每群有不止一个单元,抽样时整群抽取,并对群中的每个单元进行观测,这种抽样称之为分群抽样或整群抽样。
群本身就是抽样单元,称之为初级单元,群内的单元称为次级单元。群的划分要求群与群之间的差别越小越好。若分的群基本相似,只需要一个群就够了。它与分层的准则正好相反,它们的差别可用图
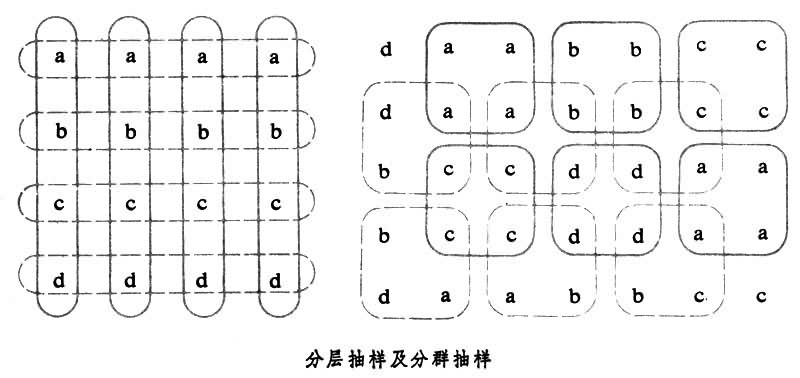
表示,图中实线为分层,虚线为分群。
分群后,群的抽取方法与群的划分有关。一般,若群的大小(群内次级单元个数)相近,可按等概率抽取;若群的大小悬殊,可考虑不等概率抽样。一个可行的不等概率抽样方法是与群的大小成比例的概率抽样,简记为PPS。
多级抽样又称多阶段抽样。如果在分群抽样中,不是对抽到的群(初级单元)中所有的次级单元都进行观测,而只是抽取一部分进行观测,这就是二级抽样。若每个次级单元又可分成更小的单元(三级单元),而对抽到的每个次级单元又只抽取部分三级单元进行观测,则称为三级抽样。由此可定义一般的 k级抽样。各级单元的抽法可以有变化,如有的分层,有的不分层;有的等概率,有的不等概率(如与被抽取的抽样单元中所包含的下一级单元的数量成比例PPS);等等。因此多级抽样给抽样设计带来很大灵活性,在大规模调查中常被采用。此外,多级抽样除了需有第一级抽样框外,只需对被抽中的单元构造下一级抽样框,故在实行中也比较经济,特别适用于资料贫乏的地区和领域。
多级抽样的分析比较复杂。以二级抽样为例,设总体共有N个初级单元,从中抽取n个,又设第i个初级单元中有Mi个次级单元,从中抽取mi个,i= 1,2,…,n。记抽中第i个初级单元中的第j个次级单元的概率为 πij,相应的观测值为xij,则
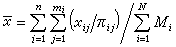
是总体均值塣一个无偏估计。?/I>的方差公式更为复杂,不仅依赖于各初级单元之间及每个初级单元内、次级单元之间的方差,还依赖于上述πij、n及mi等值的选取。
- 参考书目
- F. Yates,sampling Methods for Censuses and Surveys,4th ed.,Charles Griffin, London, 1981.
- W.G.Cochran,sampling Techniques,3rd ed.,John Wiley & Sons, New York, 1977.
- C.M.Cassel,et al.,Foundations of Inference in Survey sampling,John Wiley & Sons, New York,1977.