[拼音]:huigui fenxi
[外文]:regression analysis
研究一个或多个随机变量Y1,Y2,…,Yl与另一些变量X1,X2,…,Xk(普通变量或随机变量)关系的统计方法。在某些问题中,诸X带有“原因”的性质,故称之为自变量;诸Y带有“结果”的性质,称之为因变量。有时X与Y之间并无明显的因果关系,但仍沿用“自变量”、“因变量”的名称,有时也称诸X为“因素”,诸Y为“指标”或“响应”。
最简单的情况是l=k=1,且Y1与X1大体上有线性关系,这叫做一元线性回归(一元是指只有一个自变量)。例如,以X记每亩的肥料施用量,Y记小麦的每亩产量,在一定范围内,可认为X与Y之间大体上有线性关系。由于Y还受到其他大量的可预见和不可预见的因素的影响,更确切的是把Y 表为 Y=α+bX+ε,这里ε是一随机变量,常称为随机误差。它反映了除肥料外,其他不可控制或未加控制的因素(如土壤肥力的不均匀、种田者在操作中的各种微小的差异等)的影响。通常假定随机误差的均值为0,方差σ2>0,σ2与X 的值无关。若进一步假定ε遵从正态分布N(0,σ2),就叫做正态线性回归模型。在上述模型中α、b都是未知参数,b 称为(Y 对X 的)回归系数,而α称为常数项,它们的值由观测样本去估计。
一般,设有k个自变量X1,X2,…,Xk和因变量Y。例如,X1,X2,…,Xk分别代表每亩施肥量、每亩播种量等,Y代表每亩产量。则Y的值可以分解为两部分:一部分是由于X1,X2,…,Xk的影响,表为ƒ(X1,X2,…,Xk;β1,β2,…,βp),ƒ为已知函数,称它为回归函数。其中β1,β2,…,βp是由观测数据估计的未知参数,如上例中的α与b。另一部分是由于其他未被考虑的因素和随机性的影响,记为ε,即随机误差。故一般的回归模型有形式
Y=ƒ(X1,X2,…,Xk;β1,β2,…,βp)+ε。
方程Y=ƒ(X1,X2,…,Xk;β1,β2,…,βp),称为理论回归方程。通常,回归方程可由所研究的问题的有关理论给出,也可以根据经验数据和数学处理上的方便去选择。最常用的形式是
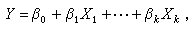
它是未知参数β0,…,βk的线性函数,故称为线性回归,βi称为Xi对Y的线性回归系数,i=1,2,…,k。有些回归方程可通过引进新自变量化为上述形式。例如,在回归方程Y=α+blogX中令 X′=logX,则方程化为Y=α+bX′形式。另一类重要例子是多项式回归。当不易从理论上确定回归函数ƒ的具体形式时,常采用 X1,X2,…,Xk的多项式作为近似, 如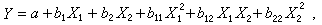 若引进新的自变量
若引进新的自变量 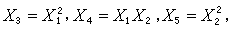 可把它化为如上的线性回归形式。因此线性回归是一类包罗很广的模型。
可把它化为如上的线性回归形式。因此线性回归是一类包罗很广的模型。
当自变量的个数k>1时,称为多元回归;当因变量的个数l>1时,称为多重回归(见多元统计分析)。
回归分析要解决的问题,一是根据试验或观测数据选定适当的回归函数,或检验某种选定的回归函数是否合用。二是对回归函数中的未知参数β0,β1,…,βp进行估计。三是检验有关这些参数的假设。四是对随机误差ε的影响程度进行估计,最常用的是估计ε 的方差σ2。五是利用已建立的回归方程进行预测和控制。
为估计未知参数,常用最小二乘法。设Y与诸X的n组观测值为
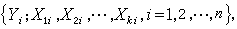
作平方和
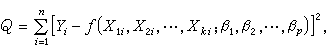
找出β1,β2,…,βp的值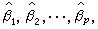 使 Q 达到极小,娕i就是βi的最小二乘估计(i=1,2,…,p)。在模型为线性时,使用
使 Q 达到极小,娕i就是βi的最小二乘估计(i=1,2,…,p)。在模型为线性时,使用
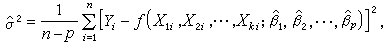
作为σ2的估计,在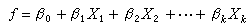 的情况下,最小二乘估计的表达式很容易求出。特别当k=1时,有
的情况下,最小二乘估计的表达式很容易求出。特别当k=1时,有
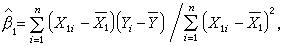
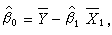
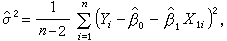
式中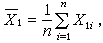
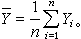
假设检验对线性回归β0 + β1X1 + β2X2 + … +βpXp最常考虑的检验问题是某些回归系数为0,例如,对假设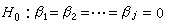 进行检验。若h0 成立,表示自变量X1,X2,…,Xj对因变量Y无显著影响,从而可以不选入方程中。这就联系到“自变量选择”的问题,在一些复杂问题中,可供考虑的自变量为数很多,要有效地进行分析,必须排除次要的因素,而将影响较大的自变量选入。常用的方法是逐步回归,它按假设检验的原则,逐次在回归方程中引进或剔除一个变量,直至变量既不能引进又不能剔除为止。
进行检验。若h0 成立,表示自变量X1,X2,…,Xj对因变量Y无显著影响,从而可以不选入方程中。这就联系到“自变量选择”的问题,在一些复杂问题中,可供考虑的自变量为数很多,要有效地进行分析,必须排除次要的因素,而将影响较大的自变量选入。常用的方法是逐步回归,它按假设检验的原则,逐次在回归方程中引进或剔除一个变量,直至变量既不能引进又不能剔除为止。
回归预测是指设想在自变量X1,X2,…,Xk的一组值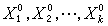 处做试验,预测得到的Y值是多少。在得到β1,β2,…,βp 的估计
处做试验,预测得到的Y值是多少。在得到β1,β2,…,βp 的估计 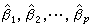 后,建立回归方程
后,建立回归方程
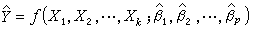 ,
,
称为经验回归方程,以给定的值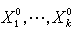 代入得
代入得
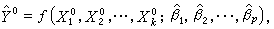
即以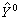 作为Y的预测值。预测是回归方程的一项重要应用。
作为Y的预测值。预测是回归方程的一项重要应用。
回归设计
在不少问题中,自变量X的取值是可控的,例如,一项生产过程中的温度、压力、反应时间等。在这种情况下,自变量的值可由试验者选定,因此可适当地选择X在试验中所取的值,以使所拟合的回归方程有优良的性能。这就是回归设计问题。关于这个问题,除了直线回归这个简单情况外,在二次(及三次)多项式回归方面有较具体的结果。其中值得一提的是旋转设计和混料设计。
旋转设计着眼于回归预测值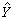 (X)的方差。设X0为自变量容许变化范围内的中心点,若在自变量空间中与X 0等距离的点处,的方差也相同,则设计称为是旋转的。对二次多项式回归的重要情况,找到了具有旋转性的设计方案。
(X)的方差。设X0为自变量容许变化范围内的中心点,若在自变量空间中与X 0等距离的点处,的方差也相同,则设计称为是旋转的。对二次多项式回归的重要情况,找到了具有旋转性的设计方案。
在混料设计中,每个自变量Xi表示一种原料在整个配方中所占的百分比,因此每个Xi都在0与1之间,且所有Xi之和应为1,试验的目的是寻找最佳配方,目前已提出了若干类型的混料试验设计并在应用上取得了一些成功。
美国统计学家J.基弗在20世纪50年代末期提出了一种回归设计优良性准则,即D 最优准则。大体上说,这种准则的要旨是使回归系数估计量的广义方差(即回归系数的协方差阵的行列式)尽可能小。基弗对这个准则进行了一些基本研究,并在一些情况下(例如当自变量变化范围为球或立方体的情况)求得了具有D 最优性的回归设计。
- 参考书目