[拼音]:wenjian tongji
[外文]:robust statistics
数理统计学的一个方面,研究当总体假定稍有变动及记录数据有失误时,统计方法的适应性问题。一个统计方法在实际应用中要有良好的表现,需要两个条件:一是该方法所依据的条件与实际问题中的条件相符;二是样本确是随机的,不包含过失误差,如记录错误等。但实际应用中这些条件很难严格满足,比方说,原来在提出该方法时是依据总体分布为正态分布的假定,但实际问题中总体的分布与正态略有偏离;或在大量的观测数据中存在受到过失误差影响的“异常数据”等。如果在这种情况下,所用统计方法的性能仅受到少许影响,就称它具有稳健性。
稳健性一词是G.E.P.博克斯在1953年提出的,但关于稳健性的思想,可追溯到20世纪初期,有些稳健性统计方法,如下文提到的修削平均,使用还要早些。从1960年J.W.图基发表他的工作以来,这方面的工作得到更多统计学家的重视。1964年P.J.休伯发表了他关于M估计的工作,进一步推动了它的发展。到1980年为止关于这方面的工作,已由休伯写成专著。
对总体分布的稳健性设当总体分布为F时,统计方法T的某项性能指标为AT(F),例如,T可以是F的数学期望的估计,而AT(F)为T的方差;若在某项实际应用中,真实的总体分布为F*,而该项性能指标取值AT(F*)。以距离p(F,F*)刻画F与F*的差异,比如,p(F,F*)可以是|F(x)-F*(x)|对x取的最大值。如果当 P(F,F*)充分小时,|AT(F)-AT(F*)|也充分小,则称方法T具有对总体分布的稳健性。可见,统计方法的稳健性与考虑的性能指标有关,也与分布的距离p(F,F*)的定义有关。因此,怎样定义适当的距离p(F,F*),研究各种距离的性质及相互关系,怎样选择适当的性能指标作为衡量稳健性的依据等,是稳健统计研究的一方面的内容。
通常使用的很多统计方法,是在总体分布为正态的前提下导出的,理论上也证明了,在正态总体的情况下这些方法具有某种优良的性能。但在大多数具体问题中,正态假定往往只是近似地满足,若一个统计方法缺乏稳健性,则它理论上可能有某种优良性能,而在实际应用中却表现很差,甚至面目全非。因此,稳健性的研究是一个有很大实际意义的课题。
图基在1960年提供了这样的例子:设x1,x2,…,xn是抽自正态总体N(μ,σ2)的样本,要估计σ,常用的估计量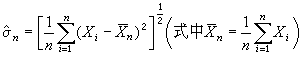 是σ的最大似然估计(见点估计),它有一系列的优良性质。另一个可供选择的估计量是平均绝对偏差
是σ的最大似然估计(见点估计),它有一系列的优良性质。另一个可供选择的估计量是平均绝对偏差
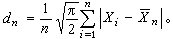
如果以估计量的方差来衡量其优良性(方差愈小愈好),则当总体分布确为N(μ,σ2)时,捛n优于dn,因为可以算出,当n→∞时,捛n的方差与dn的方差之比值趋于0.876,比1小。但是,如果实际问题中的总体被一个方差较大的正态总体N(μ,9σ2)所“污染”,即有一个很小的 ε>0,使真实的总休分布为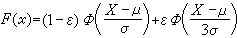 ,其中
,其中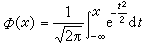 是标准正态分布函数,则可以算出,当ε=0.05时,捛n和dn的方差比的极限超过2。就是说,即使像0.05这么小的污染程度也足以使捛n远不如dn的一半。因此捛n作为σ的估计稳健性较差,而相对地说dn的稳健性就较捛n好。
是标准正态分布函数,则可以算出,当ε=0.05时,捛n和dn的方差比的极限超过2。就是说,即使像0.05这么小的污染程度也足以使捛n远不如dn的一半。因此捛n作为σ的估计稳健性较差,而相对地说dn的稳健性就较捛n好。
理论研究表明:像F检验(见假设检验、方差分析)之类的与总体方差有关的统计方法,其性能多与总体的正态性有较强的依赖关系,稳健性较差;而与总体均值有关的统计方法,如t检验之类,稳健性相对说来要好一些。
对异常数据的稳健性由于在大量次数的试验或观测中,很难完全避免出现个别疏忽,因此,要使统计方法有较好的稳健性,就必须要求,它所依据的统计量不受个别异常数据的太大影响。一个典型的例子是用样本均值或样本中位数(见统计量)去估计正态分布的均值,前者受个别异常数据的影响较大,而后者则几乎不受到影响,故从稳健性角度看,后者优于前者。介于两者之间的有所谓修削平均,即给定自然数k<n/2(n为样本大小),把全部样本x1,x2,…,xn中最大的k个和最小的k个舍弃,余下的n-2k个的算术平均值称为修削平均值,k愈大,修削愈多,如果有少量异常数据混入,则在修削时被舍弃了,因而不致造成危害。这是一个较早的稳健统计方法,但被广泛使用。
为获得对异常数据的稳健性,有两个途径:一是设计出有效的方法以发现数据中的异常值,从而把它们剔除。这已成为数理统计学中的一个重要课题,积累了不少成果。另一个途径是设计这样的方法,使样本中的个别数据不致对最终结果有过大的影响,如用最小二乘法求参数估计时,是根据使偏差平方和为最小的原则,从而若有个别偏差特大的数据,其对结果的影响很大,故基于最小二乘法的统计方法的稳健性一般较差,若改用绝对偏差和最小的原则,则稳健性有所改善。
稳健性与效率使统计方法具有稳健性,在一定的意义上可以看成是一种“保险”:付出一定的保险费,以避免遭受重大损失,保险费就表现为方法在效率上的降低。例如,用样本中位数估计正态分布均值,在稳健性上比用样本均值好;但如情况没有异常,即总体分布确为正态,并且无异常数据,则样本中位数以方差大小衡量的效率,约只有样本均值的三分之二。稳健统计的一个任务,就是设计有稳健性的统计方法,而使其在效率上的损失尽可能小。
与非参数统计的关系非参数统计方法往往有较好的稳健性,而一些稳健统计方法常要用到非参数性质的统计量,因此二者关系密切。但从性质上看二者是不同的:非参数统计中,对总体分布的假定很少;而稳健统计则一般是从一个确定的参数性模型(如正态模型)出发,考虑当模型条件有少许扰动时的后果。因此,稳健统计本质上属于参数统计的范畴。
- 参考书目
- P.J. Huber,Robust Statistics,John Wiley & Sons,New York,1981.