[拼音]:shouming shuju tongji fenxi
[外文]:statistical analysis of life data
数理统计学中处理寿命数据的理论与方法,主要包括以工业产品寿命为对象的可靠性统计和以生物体的生存期为对象的生存分析。这里所说的寿命和生存期的含义都是广义的。对不可修复的产品(如电子管),寿命是指它从开始工作起至丧失其规定功能(称为失效)为止的工作时间;而对可修复的产品(如计算机),寿命是指它两次相邻故障间的工作时间。生物体的生存期是与它生命过程中的某个特殊事件(如患某种疾病)相联系的,指从该事件发生起至因此而死亡所经历的时间。如果将出生作为所考虑的事件的开始而又不区分死亡的原因,则所得的生存期就是通常意义下的寿命。上述在不同场合下使用的寿命或生存期的概念,在数学上有共同点,可以统一处理。
寿命分布及其数学描述对任一特定个体(产品或生物体),从某个标准时间起在规定时间 t内失效(或死亡),是一个随机事件。因此寿命(生存期)是一个非负的随机变量,通常记为T,其概率分布称为寿命分布。描述一个寿命分布,除了通常的分布函数F(t)和密度函数ƒ(t)外,也常用下述两个更为直观且与上面两种函数可以互相转换的函数:
(1)可靠度函数也称生存函数,是指个体在t时尚未失效(尚存活)的概率
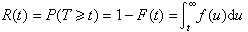 ;
;
(2)危险率函数也称失效率函数,是指在 t时刻尚未失效的个体在 t以后的一个单位时间内失效(或死亡)的概率λ(t)。更严格地说,λ(t)是在已知T≥t的条件下T的条件密度。它与前述各量之间的关系为
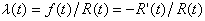 。
。
因而可靠度函数也可用危险率函数表示:
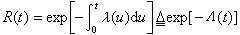 ,
,
式中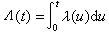 又称累积危险率。寿命T 的数学期望称为平均寿命;α分位数称为可靠度为1-α的可靠寿命。特别,中位数称为中位寿命,也就是有50%个体所能达到的寿命值,它们都是常用的寿命特征量。
又称累积危险率。寿命T 的数学期望称为平均寿命;α分位数称为可靠度为1-α的可靠寿命。特别,中位数称为中位寿命,也就是有50%个体所能达到的寿命值,它们都是常用的寿命特征量。
常见的寿命分布有指数分布、韦布尔分布、对数正态分布和伽玛分布等(见概率分布)。其中以指数分布最为重要,它是惟一具有恒定危险率,因而具有“无后效性”的分布,即一个尚存活(未失效)的个体,不管它已生存工作了多长时间,其未来的存活时间与一个“新”的个体没有差别。在一定条件和一定的近似程度之下,许多工业产品的寿命都可以看成是遵循或近似遵循指数分布的。指数分布在寿命数据分析中占有重要地位的另一原因是它的统计分析最为简单,理论上也最为成熟。
寿命数据特点和寿命试验种类一般的寿命数据与统计中通常使用的随机样本有很大区别。寿命数据往往是不完全数据,即并不是每一个观测到的值都是确切的寿命值。某些数据可能只表示相应个体的寿命不小于该数值,而并不知道其确切寿命的数值,这样的数据称为截尾数据。如从现场收集的寿命数据,由于在统计时某些产品尚未失效,或因多种原因中断观测,这些产品的实际寿命应比已观测到的时间长。生存期数据一般也具有这种特点。就是在可以人为控制的产品寿命试验中,由于试验费时较长,费用较高,往往不能将试验进行到所有受试样品都失效时为止。因此必须在达到规定的时间或在失效的样品达到规定数目时终止试验。这种试验称为截尾试验,前者称为定时截尾试验,后者称为定数截尾试验。对某些长寿命的产品,为进一步缩短试验所必须的时间且获得足够的失效数据,试验时常采用加大应力(诸如热应力、电应力,机械应力等),以促使产品加速失效。这种试验称为加速寿命试验。此外,根据试验中是否用“新”的样品替换已失效的样品,寿命试验还可以分成有替换试验和无替换试验两类。
统计分析方法对于非截尾的(完全)寿命数据,可以应用一般的统计分析方法;对于截尾寿命数据,则必须用特殊的分析方法,常用的有如下方法。
(1)基于次序统计量(见统计量)的分析方法 如果寿命分布的类型已知,则对于定时或定数截尾的寿命数据,根据次序统计量的统计推断方法可以对有关分布参数或寿命特征量进行估计或检验,例如对指数分布,不论何种截尾形式,也不论试验有无替换,平均寿命θ的最大似然估计都为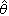 =S/r,式中r为试验中出现的失效数,S为所有试验样品的试验时间的总和。还可进一步对θ进行区间估计。对其他的寿命分布,其参数或寿命特征量的估计与检验,要比指数分布复杂得多。例如威布尔分布,为求参数的最大似然估计,必须用迭代法解似然方程组。为此发展了许多线性估计方法,使用方便,但需用大篇幅的图表。
=S/r,式中r为试验中出现的失效数,S为所有试验样品的试验时间的总和。还可进一步对θ进行区间估计。对其他的寿命分布,其参数或寿命特征量的估计与检验,要比指数分布复杂得多。例如威布尔分布,为求参数的最大似然估计,必须用迭代法解似然方程组。为此发展了许多线性估计方法,使用方便,但需用大篇幅的图表。
有关寿命数据的假设检验的主要问题之一,是确定寿命分布的类型。此时就需要用适用于截尾样本的分布拟合优度检验的特殊方法。例如为检验总体服从指数分布的假设,Б.Β.格涅坚科等提出以下一种检验方法:如果t1,t2,…,tr是全部投试的 n个样品中前r(r≤n)个失效的定数截尾寿命数据,那么当总体分布为指数分布时,统计量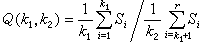 服从自由度为2k1,2k2的F分布,式中
服从自由度为2k1,2k2的F分布,式中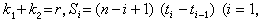
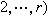 而t0=0。在实际应用中常见的另一类检验问题是两组寿命数据的比较,即检验两个寿命总体的可靠度(生存)函数是否相等,在已知分布类型时,可以化成关于分布参数或某些寿命特征量的假设检验问题。
而t0=0。在实际应用中常见的另一类检验问题是两组寿命数据的比较,即检验两个寿命总体的可靠度(生存)函数是否相等,在已知分布类型时,可以化成关于分布参数或某些寿命特征量的假设检验问题。
(2)寿命表分析和乘积限估计以及其他非参数方法当寿命分布类型未知时,可采用各种非参数统计分析方法。寿命表分析适用于大样本的寿命(生存)数据,它脱胎于人口统计中的人口寿命表,但经过修改可适用于各种寿命数据。数据按大小分组,通过对截尾数据的校正,可得出各组的可靠度函数、密度函数和危险率函数的估计,以及平均寿命等寿命特征量的估计,并可计算这些统计量的方差的近似值。乘积限估计适用于小样本数据,其思想和方法与寿命表分析相似。
关于假设检验,也有许多非参数方法可以采用,例如对两组寿命数据的比较,可用广义威尔科克森检验和时序检验等。
(3)危险率的回归模型 在实际中, 个体的失效受到它本身某些固有因素和外界因素的影响。为此有必要对寿命数据进行统一的定量分析,以便在尽可能排除个体差异的情况下,对感兴趣的因素的作用进行考察。在数学上,就是要考虑若干定性或定量因素Z1,Z2,…,Zp对寿命的影响。一种有效的方法是将它们的影响表现在对危险率λ(t)的关系中,考虑λ(t)或logλ(t)对诸因素的回归模型。讨论最多的是所谓比例危险率模型
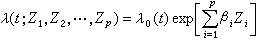 ,
,
式中λ0(t)是当Z1=Z2=…=Zp=0时的基准条件下的危险率,而β1,β2,…,βp是待估计的回归系数。根据λ0(t)的类型是否已知,模型又可分为参数与非参数两种。无论对哪种类型,都可以对β1, β2,…,βp以及λ0(t)的类型及所包括的参数进行估计,并对有关的βj的假设进行检验。
发展简史很早以来人们就有一些处理寿命数据的方法。寿命表就是最早应用的一种统计分析的工具,它的使用可追溯到300多年前。由于人口统计学的发展,特别是人寿保险数学的发展,寿命数据的分析逐渐采用现代统计理论和方法,且寿命的概念也逐渐从人和生物体的寿命扩大到工业产品的寿命。W.韦布尔发现Ⅱ型极值分布可以广泛地拟合各类寿命数据以后,寿命数据分析的手段就更为有效。特别是在第二次世界大战期间,由于复杂武器及电子设备的发展使产品可靠性问题愈来愈突出,因而产生了可靠性这个综合了工程、物理、数学和统计学内容的边缘性学科(见可靠性数学理论),并在战后得到迅速发展。从可靠性统计中发展起来的寿命数据分析方法又反过来应用于医学和生物学,从而又促使生存分析的发展。由于生命过程更为复杂,个体差异更大,因此必须考虑某些更为复杂的模型,而这些模型及其处理方法又可应用到可靠性问题中去。在这个意义上说,可靠性和生存分析是两个既有联系又各具特点的分支学科。它们所研究的具体对象不同,所考虑的模型也有区别,但它们的统计分析是有共性的。
- 参考书目
- N.R.Mann, R.D.Schafer and N.D.Singpurwalla,Methods for Statistical Analysis of Reliability and Life data,John Wiley & Sons, New York, 1974.
- A.J.Gross & V.A.Clark,Survival Distributions: Reliability Applications in the Biomedical Sciences,John Wiley & Sons, New York,1975.