[拼音]:fenbushi chuli
[外文]:distributed processing
由多个自主的、相互连接的信息处理系统,在一个高级操作系统协调下共同完成同一任务的处理方式。
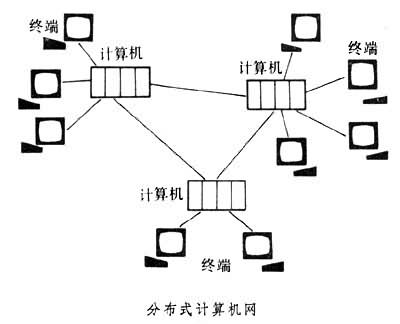
在70年代计算机网络出现之前,信息处理采用集中式处理或分散式处理。集中式处理把各信息包括远程信息都传输到统一的信息处理系统中进行处理。采用集中式处理可以达到设备利用率高的目的,并能保证被处理信息的完整性和有效性。一个下设许多工厂的公司采用集中式信息处理可以得到整个公司的最佳结果,不象各工厂分散处理那样,考虑的只是每个工厂的优化。集中处理需要的设备比分散处理所用的设备复杂得多,但它可为大部分工厂所共享,避免设备的重复。分散式处理的最大优点是简单,能就地提取数据、变换格式并进行加工,最后输出决定。要把这些工作集中于统一的程序中是非常困难和代价昂贵的。分散程度越大,满足部门的特殊信息处理要求的可能性也越大,但统一和控制信息流的困难也越大。由于要求在数据产生场所进行局部处理的数据比重不断增加,要求应答时间缩短和计算机的处理能力不可能无限增强等原因,常把分散设置的各计算机组合成计算机网,形成分布式处理系统。这样既能克服分散处理的缺点,又可避免集中的困难(见图)。70年代以来,随着计算机日益广泛地应用于各个领域,全国性与国际性的计算机网相继出现,这种信息处理系统的功能和结构也越来越复杂。分布式处理将装备从集中的处理系统中分散开来,便能直接从信息源取得信息并进行相互协调的处理。这种处理方式适应计算机网发展的需要。
一般信息处理系统的硬件、控制点和数据库有多种构成方式。从硬件组成来看属于分布式系统的有两种:
(1)系统由多个处理机组成,但是有统一的输入输出系统;
(2)多计算机系统,有多个输入输出系统。从控制点的设置方式来看属于分布式处理的有 3种:
(1)多个系统在子任务一级上协同操作执行某一任务;
(2)多个相同的控制系统协同执行同一任务;
(3)多个不同的控制系统协同执行同一任务。从数据库来看属于分布式的有 3种:
(1)只有部分数据库在主结点中有复制本;
(2)只有部分数据库在主结点中有目录;
(3)数据库全部分散存放,没有主结点。
分布式处理系统必须有能力在短时间内动态地组合成面向不同服务对象的系统。对用户来说系统是透明的,用户只需指定系统干什么而不必指出哪个部件可以提供这一服务。系统各组成部分是自主的,但不是无政府状态,而是遵循某个主计划由高级操作系统进行协调工作。在一个计算机网中有多台主机不一定都是分布式处理。如果这样的系统不具备动态组合及任务再指派的能力,那么它们仍然是集中式处理。高级操作系统是分布式处理的关键。在分布式系统中不再使用完整的信息,各个组成部分提供自己的状态信息,高级操作系统根据这些状态信息进行任务协调和资源再分配,各组成部分之间没有层次关系而是自主的。