[拼音]:julei fenxi
[外文]:clustering analysis
在没有或不用样本所属类别信息的情况下,依据样本集数据的内在结构,在样本间相似性度量的基础上对样本进行分类的方法。例如给一个幼童看若干张不同形式汽车和轮船的画片,教师即使不告诉他哪一张是汽车,哪一张是轮船,他也能自然地把所有画片分成两类。这是一种非监督学习方法(见监督学习)。分类的基础是模式间的相似和不相似关系,这种关系常常用模式特征向量之间的距离来度量。
基本的聚类方法有谱系聚类法(或称系统聚类法)和动态聚类法。
谱系聚类法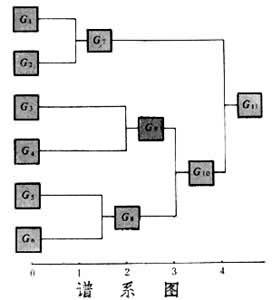
首先把每个模式特征向量各自看成一类,然后选择一种计算类别之间距离的度量,把类间距离最小的两类合并成一个新类,计算新类与其他类的距离,再将距离近的两类合并,这样每次减少一类,直至所有的模式数据合并成一类为止。用谱系图(见图)表示合并的过程,横坐标的刻度是并类的距离。如果确定一个阈值T,把类间距离小于阈值的类合并在一起,那么从谱系图就可得到模式数据的聚类结果。在图中,若令T等于1.5,则G1和G2是一类,G3是一类,G4是一类,G5和G6是一类。用于系统聚类法中的类间距离有最小距离、最大距离、中间距离、重心距离、类平均距离、可变类平均距离、可变距离和离差平方和距离。将p类、q类合并成一个新的k类之后,计算k类和其他r类之间的类间距离时,上述八种距离有如下统一的递推公式:
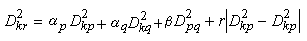
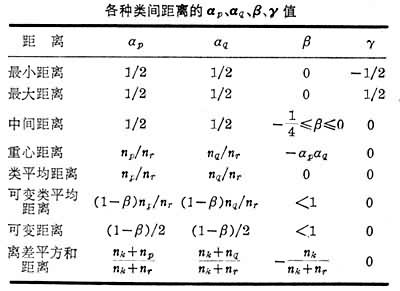
式中Dkr表示k类和r类之间的距离,Dkp表示k类和p类之间的距离,其余的按此类推。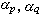 ,β,γ等系数对于不同z距离取不同的数值,如下表。表中np为原p类的样本数, nk为新组成的k类样本数等。系统聚类法除了用来对数据进行聚类外,也可用来设计树分类器的树状结构
,β,γ等系数对于不同z距离取不同的数值,如下表。表中np为原p类的样本数, nk为新组成的k类样本数等。系统聚类法除了用来对数据进行聚类外,也可用来设计树分类器的树状结构
 动态聚类法
动态聚类法
这是一种迭代使用最小距离分类原则(见最小距离分类)的聚类算法。假定总的类别数是已知的,且先给定每一个类的初始代表样本(称为类中心)。所有样本按照其特征向量离哪一个类中心的特征向量最近就把它分到哪一类。在全部样本分完以后,计算属于同一类样本的平均特征向量并将它作为该类的新的类中心特征向量。再按照最小距离分类原则对所有样本进行新的分类。如此反复进行计算,直到所有样本所属类别不再变化为止。在类别总数未知的情况下,先设定一个类别总数,然后按上述方法进行聚类计算。但在每次对所有样本分类后,把类中心特征向量过分接近的两类合并成一类,而把按类计算的样本数据方差超过某一规定阈值的类分开成两类。这样经过合并或分开后,再重新计算类中心和对所有样本进行新的分类。如此反复进行,直到分类情况不再变化,或者迭代次数达到预先给定的次数为止,这就是聚类分析中的ISODATA算法。理论上可以证明,不论初始类中心如何选择,动态聚类算法总是可以收敛的。在更复杂的情况下,代表类别的类中心不是类的平均特征向量,而是具有某一特定形状的、由若干样本组成的核。
- 参考书目
- M.R.Anderberg, Cluster Analysis for Applications,Academic Press,New York, 1973.