[拼音]:ziran yuyan lijie
[外文]:natural language understanding
使计算机“理解”人类语言以便人机之间直接用自然语言通信的技术。自然语言理解的研究能从根本上为普及计算机扫清道路,并为揭示人类语言机制和思维奥秘创造条件,因此自然语言理解已成为人工智能活跃的研究领域。自然语言理解的研究对象一般指书面语。口语理解因涉及语音过程和结果的处理,已形成单独的研究领域(见言语理解)。
20世纪40年代中期,人们开始研究根据输入原文用计算机来编制语词索引(词的出处、出现频率),在此基础上进一步提出了机器翻译问题,目的在于研制能翻译科技文献的实用系统。当时采用的方法是,先在双语对照词典上对输入语句每一个词按顺序逐一选择目标语言中与之对应的词,并调整词序以得到符合目标语言习惯的输出句。实践表明,依靠简单匹配技术和单纯语法结构知识难以保证翻译质量。在经过一段时期的低潮之后,人们终于认识到要机器翻译自然语言乃至用机器进行一切形式的自然语言处理,首先要使计算机“理解”自然语言,也就是走人工智能的道路。这便是自然语言理解的研究在60年代应运而起的原因。
60年代初期,最早一批自然语言理解程序是在特定领域内且受到较大限制的条件下编制的。输入限定为简单的陈述句或疑问句,同预先规定的关键词或模式进行匹配,然后运用启发式知识作出响应。这些系统缺乏演绎推理能力,只适用于专门领域的简单问答系统。文本型自然语言处理系统则是对上述简单系统的改进。
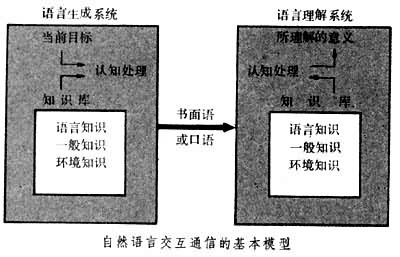
文本的原文以某种符号形式存放于系统内,然后用较灵活的索引技术检索所需材料,而不作语义处理。这类系统已可用于一般领域但仍缺乏演绎推理能力。60年代中期,人们开始研究有限推理型系统。输入语句以某种内部形式存放于系统内并进行语义分析,系统能以有限的推理能力提供数据库中并未显式存储的事实。这就是演绎数据库的原型。70年代以后开始研究的知识型自然语言理解系统,也可纳入知识工程范围。系统拥有大量一般知识、环境知识和语言本身的知识。设计这类系统的一个指导思想是将语言过程看成认知过程的反映,下图为语言双方交互通信的基本模型。70年代初期研制的具有较大影响的两个著名知识型自然语言理解系统是W.A.伍兹的LUNAR系统和T.维诺格勒的SHRDLU系统。LUNAR是用自然语言通信的实验性信息检索系统。它的作用是辅助地质学家对“阿波罗”11号航天飞船从月球带回的土壤和岩石标本进行分析。此外这种系统采用的扩展转移网络和过程语义技术对人工智能研究具有普遍意义。SHRDLU系统模拟操作积木块的机器人,其目的在于表明:要使计算机程序理解自然语言,必须将语法、语义和推理等有机地结合起来。这项研究对知识表示的研究有推动作用。80年代还出现了将自然语言理解系统与专家系统结合起来的趋势。例如概念汲取系统对输入的科技文献在理论的基础上进一步评价分析,试图提出一些有用建议。
要使计算机能“理解”自然语言,必须在语言学基本理论指引下并以机器可以接受的方式提供实用的自然语言语法分析的技术。
自然语言理解主要用于机器翻译、数据库检索、集成型问答系统、原文分析、响应生成、智能机的人机接口等方面。也有一些系统的研制是为了进行语言学或认知心理学的理论研究而不在于直接应用。
- 参考书目
- T.Winograd,Language as a Cognitive Process,Vol.1, Addison-Wesley Publ. Co., Reading, Mass.,1983.