[拼音]:yanyu hecheng
[外文]:speech synthesis
用人工产生语音乃至整段语言的技术。合成语音的装置叫做言语合成器或言语合成系统。早期的合成器是机械式的或电路式的,如今,言语合成已经计算机化了。言语合成技术不仅是深入研究语音特性的一种手段,而且也是实现人 -机语言通信的一种手段。
在语音研究中,利用言语合成技术,可以灵活而精确地控制语音的特性参数,合成出各种各样的语音样本,通过对这些样本的听辨,逐步揭示出语音现象的机理。
言语合成与语音学用合成技术来验证语音的特性,是言语合成主要功能之一。它可以验证哪些语音要素在传输中是必需的,哪些是多余的。可以检查语音中某一频段在传输中的有效程度;可以通过试验言语的“信噪比”来确定言语清晰度的最佳参量等等。语言学家在20世纪50年代晚期开始用合成来探索语音学上的问题,他们用加减参量、依存制约、转换切分等方法,对元音音位区域、复合元音的主次特征、辅音的发音方法和部位在辨音中的贡献、声调在辨义上的功能,以及一切韵律特征等的研究,提供了极其方便而有效的手段。
言语合成系统的类型及其发展机械式的合成是比较早期的方法,用机械装置模拟人的发音,用人工控制可以发出简单音节。后来有人用电路方法模拟语音信号。声谱分析发展后,大量出现根据言语声谱来合成语音的装置。电子计算机问世,一切复杂的机械或电路的合成系统都用计算机来代替,并在功能方面有了进展。言语合成约可分为 5个阶段:
(1)40年代以前,是用机械或电路模拟语音的时代。
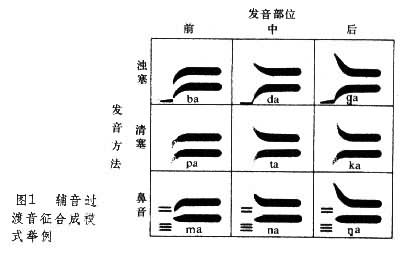
(2)50年代有了新的进展,言语声谱分析已达到相当完备程度。辅音与元音之间的“过渡音征”画成模式,通过模式还音器能产生很标准的辅音,至今还有参考价值(图1)。
(3)60年代, 计算机应用于语音合成系统,言语的“规则合成”成为最先进的合成自然语言的途径。
(4)70年代以来,在规则合成的基础上,主要向合成的商品化发展,大量的多语言对译器充斥市场,多限于有限辞汇和低质量的音质。
(5)80年代以来,提高合成的音质以及“文-语合成”,盲人阅读机等都有了相当成绩。这种连续语言的合成要求,展开了第5代言语合成的序幕。未来的言语合成,将是除了更仿真地合成语音外,还要包括一切语法、语气等特征,为人-机对话系统奠定基础。
 计算机与言语合成
计算机与言语合成
计算机能以极高的速度进行运算和控制,又能接受、存储和输出庞大的信息。然而,迄今为止,人和计算机之间的信息交换,几乎都是依靠键盘打字、屏幕显示和打印输出。人的话语是一种最自然、最有效的通信媒介,语音合成就是人 -机对话最重要技术之一。
计算机的言语合成系统大体有 3类:规则合成、单元编辑合成和录音编辑合成。
(1)规则合成系统(图 2)扎根于语音产生的声学理论。按此理论,任何一个语音都由声源激励、声道共鸣和口鼻辐射这3个过程产生。语音不同,产生该语音的一套声学参数也不同。这些参数有:控制音高的基频(对浊音而言),控制音强的振幅,控制音长的时间,控制音色的频谱包络,共振峰频率及带宽,线性预测系数 (LPC),声道截面函数或调音参数等。用这类参数按照一定的规则来控制具体的合成器,就能合成出预定的语音或语句。
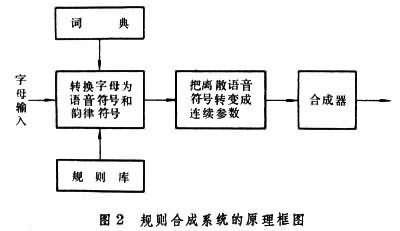
第1步,通过语音分析技术获得各种语音的上述基本参数, 再通过语音学上的分析,归纳出由音素组成音节、由音节构成词组或句子时的各种规则,然后,将这些参数和规则存入计算机的存储设备中。合成时,计算机首先根据所选用的转换规则将输入的文本字母转换为一串音素符号。这一过程,或者通过字母 -音素转换程序来完成,或者通过查寻存储好的发音词典来完成。与此同时, 计算机还检查文本的句法,根据规则和词典决定音素序列的韵律符号。第 2步,将这些离散的符号序列转变成一串连续变化的参数序列和数学函数,这些参数随时间平滑变化,它们携带着待合成的语音的频谱特征和韵律特征。第 3步,用这些依时变化的声学参量再去控制具体合成器或合成程序,合成出预定的语音或语句。
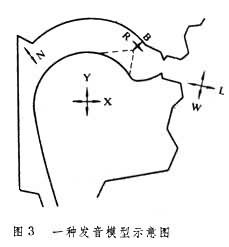
具体合成器有终端合成器和调音合成器等类型。终端合成器多以共振峰为控制参数(也称共振峰合成器),用滤波器组来模拟语音的频谱特征,使得最终合成出的语音谱包络逼近自然语音的谱包络。调音合成器则是以发音模型为基础,用几个发音参量来描写发音过程,这些参量通过规则转换出声道截面函数序列,进而控制合成器,合成出相应的语音。(图3)是一种发音模型的示意图,图中L和W描写唇的合、撮和开口度, R和B描写舌尖的移动,X和Y描写舌体活动,N描写软腭的升降。对语音研究来说,共振峰合成器和调音合成器都有实用价值。
(2)单元编辑合成系统。事先存入一套语音单元中每一单元的一小段数字波形,存入的单元可以是音素或音节, 或者是某音素的脉冲响应波形。例如,存入所有浊音音素的一个周期的波形。合成时,将这些单元选择性地连接起来。
(3)录音编辑合成系统。事先把待输出的语句、短语、单词等进行录音、压缩和编码,然后存入计算机。使用时,在既定的指令串控制下,计算机对存入的信息进行检索、编辑和解码,输出话音。这种系统有如一种低数码率的录放机。
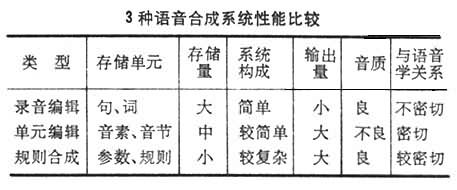
在录音编辑合成系统中,存入的是原始语音的波形,所以还原出的语音音质比较自然,系统的构成也比较简单,整个合成过程所涉及的语音学知识不多。但由于受到计算机存储容量的局限,人们不可能把日常交谈和阅读时所使用的各种词汇和语句都存入计算机,只能按不同用途存入有限的语句和词汇,应用上受到较大的限制。
在单元编辑合成系统中,存入的是音节或音素,而一种语言的音节或音素数目总是有限的,例如汉语的音素只有30多个,以这些音素拼成的音节只有 400多个。显然,这种方式能以较小的存储量来满足较大的词汇量输出的要求。例如,自然发出的“合成器”一词有一秒的时长,在录音编辑合成系统中,对此一秒的声波要取 1万个点(即采样频率10千赫),每一点的数位编成12位的代码,那么,存储量将是 120千位。但“合成器”一词由 7个音素组成( 用汉语拼音注音为hé chéng qì),如果在某单元编辑合成系统中,为每一音素存10毫秒的波形 ,合成此词时只需0.84千位。但是,实际的发音动作是连贯的,一个音节由几个音素构成时,各音素间有许多变体,音节和音节之间呈现出错综复杂的协同发音等关系。所以,编辑拼接时要作大量语音学上的处理。目前,这类处理技术还不太完善,因此这种系统虽然能输出的词汇量比录音编辑的多得多,存储量又小得多,但合成的音质不如录音编辑系统。
在规则合成系统中,存入的是描写语音特性的各种参量而不是波形本身,所以所需存储量比两种编辑合成系统小得多,而它能输出的词汇量是很大的,甚至是无限的。不过,在规则合成系统中,处处依赖编定的规则,语音现象又那么复杂,各音素或音节之间又相互影响,以致要归纳出比较系统的和完善的规则是不容易的。
目前,国内外对上述 3种类型的语音合成系统都正在大力开发之中,有的系统已开始用于自动报时、天气预报、自动报电话号码、汽车自动报警、语音教学、导游语词翻译、发音玩具等方面。有的系统和语音自动识别系统合为一种应答系统,用于车站、机场自动售票业务等。在一种盲人助读系统中,输入文字后,系统就能流利地朗读起来。
- 参考书目
- J.L.Flanagan,L.R.Rabiner(ed.),Speech Synthesis,Dowden,Hutchinson and Ross Inc.,Stroudsburg,1973.