[拼音]:xinyuan bianma
[外文]:source coding
为了减少信源输出符号序列中的剩余度、提高符号的平均信息量,对信源输出的符号序列所施行的变换。具体说,就是针对信源输出符号序列的统计特性来寻找某种方法,把信源输出符号序列变换为最短的码字序列,使后者的各码元所载荷的平均信息量最大,同时又能保证无失真地恢复原来的符号序列。
既然信源编码的基本目的是提高码字序列中码元的平均信息量,那么,一切旨在减少剩余度而对信源输出符号序列所施行的变换或处理,都可以在这种意义下归入信源编码的范畴,例如过滤、预测、域变换和数据压缩等。当然,这些都是广义的信源编码。
一般来说,减少信源输出符号序列中的剩余度、提高符号平均信息量的基本途径有两个:
(1)使序列中的各个符号尽可能地互相独立;
(2)使序列中各个符号的出现概率尽可能地相等。前者称为解除相关性,后者称为概率均匀化。
信源编码的一般问题可以表述如下:若某信源的输出为长度等于M的符号序列集合
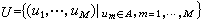
式中符号A为信源符号表,它包含着K个不同的符号,A={ɑk|k=1,…,K},这个信源至多可以输出KM个不同的符号序列。记‖U‖=KM。所谓对这个信源的输出进行编码,就是用一个新的符号表B的符号序列集合V来表示信源输出的符号序列集合U。若V的各个序列的长度等于 N,即
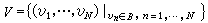
式中新的符号表B共含L个符号,B={bl|l=1,…,L}。它总共可以编出LN个不同的码字。类似地,记‖V‖=LN。为了使信源的每个输出符号序列都能分配到一个独特的码字与之对应,至少应满足关系
‖V‖=LN≥‖U‖=KM
或者
N/M≥logK/logL
假若编码符号表B的符号数L与信源符号表A的符号数K相等,则编码后的码字序列的长度N必须大于或等于信源输出符号序列的长度M;反之,若有N=M,则必须有L≥K。只有满足这些条件,才能保证无差错地还原出原来的信源输出符号序列(称为码字的唯一可译性)。可是,在这些条件下,码字序列的每个码元所载荷的平均信息量不但不能高于,反而会低于信源输出序列的每个符号所载荷的平均信息量。这与编码的基本目标是直接相矛盾的。下面的几个编码定理,提供了解决这个矛盾的方法。它们既能改善信息载荷效率,又能保证码字唯一可译。
离散无记忆信源的定长编码定理
对于任意给定的ε>0,只要满足条件
N/M≥(H(U)+ε)/logL
那么,当M足够大时,上述编码几乎没有失真;反之,若这个条件不满足,就不可能实现无失真的编码。式中H(U)是信源输出序列的符号熵。
通常,信源的符号熵H(U)<logK,因此,上述条件还可以表示为
[H(U)+ε]/logL≤N/M≤logK/logL
特别,若有K=L,那么,只要H(U)<logK,就可能有N<M,从而提高信息载荷的效率。由上面这个条件可以看出,H(U)离logK越远,通过编码所能获得的效率改善就越显著。实质上,定长编码方法提高信息载荷能力的关键是利用了渐近等分性,通过选择足够大的M,把本来各个符号概率不等[因而H(U)<logK]的信源输出符号序列变换为概率均匀的典型序列,而码字的唯一可译性则由码字的定长性来解决。
离散无记忆信源的变长编码定理
变长编码是指V的各个码字的长度不相等。只要V中各个码字的长度 Ni(i=1,…,‖V‖)满足克拉夫特不等式
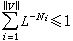
这 ‖V‖个码字就能唯一地正确划分和译码。离散无记忆信源的变长编码定理指出:若离散无记忆信源的输出符号序列为 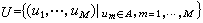 , 式中 A={ɑk|k=1,…,K},符号熵为H(U),对U进行唯一可译的变长编码,编码字母表B的符号数为L,即B={bl|l=1,…,L},那么必定存在一种编码方法,使编出的码字Vi=(vi1,…,viNi),(i=1,…,‖V‖),具有平均长度嚻:
, 式中 A={ɑk|k=1,…,K},符号熵为H(U),对U进行唯一可译的变长编码,编码字母表B的符号数为L,即B={bl|l=1,…,L},那么必定存在一种编码方法,使编出的码字Vi=(vi1,…,viNi),(i=1,…,‖V‖),具有平均长度嚻:
MH(U)/logL≤嚻<MH(U)/logL+1
若L=K,则当H(U)<logK=logL时,必有嚻<M;H(U)离logK越远,则嚻越小于M。
具体实现唯一可译变长编码的方法很多,但比较经典的方法还是仙农编码法、费诺编码法和霍夫曼编码法。其他方法都是这些经典方法的变形和发展。所有这些经典编码方法,都是通过以短码来表示常出现的符号这个原则来实现概率的均匀化,从而得到高的信息载荷效率;同时,通过遵守克拉夫特不等式关系来实现码字的唯一可译。
霍夫曼编码方法的具体过程是:首先把信源的各个输出符号序列按概率递降的顺序排列起来,求其中概率最小的两个序列的概率之和,并把这个概率之和看作是一个符号序列的概率,再与其他序列依概率递降顺序排列(参与求概率之和的这两个序列不再出现在新的排列之中),然后,对参与概率求和的两个符号序列分别赋予二进制数字0和1。继续这样的操作,直到剩下一个以1为概率的符号序列。最后,按照与编码过程相反的顺序读出各个符号序列所对应的二进制数字组,就可分别得到各该符号序列的码字。
例如,某个离散无记忆信源的输出符号序列及其对应的概率分布为
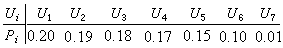
对这些输出符号序列进行霍夫曼编码的具体步骤和结果如表。
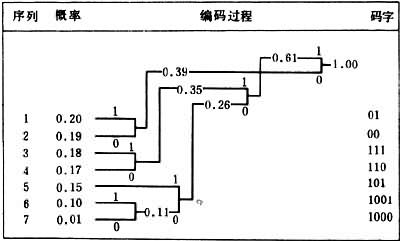
由表中可以看出,在码字序列中码元0和1的概率分别为10/21和11/21,二者近乎相等,实现了概率的均匀化。同时,由于码字序列长度满足克拉夫特不等式
2×2-2+3×2-3+2×2-4=1
因而码字是唯一可译的,不会在长的码字序列中出现划错码字的情况。
以上几个编码定理,在有记忆信源或连续信源的情形也有相应的类似结果。在实际工程应用中,往往并不追求无差错的信源编码和译码,而是事先规定一个译码差错率的容许值,只要实际的译码差错率不超过这个容许值即认为满意(见信息率-失真理论和多用户信源编码)。