[拼音]:xinyuan
[外文]:information source
产生消息(符号)、消息序列和连续消息的源,在数学上可以用随机变量、随机序列和随机过程来表示。信息是抽象的,信源则是具体的。例如人们谈话,人的发声系统就是语声信源;观看电视,被摄制的客观物体和人物就是图像信源。另外还有文字信源、数据信源、遥感信源等。
分类
最基本的信源是单个消息(符号)信源,它可以用随机变量X及其概率分布P来表示。通常写成(X,P)。根据信源输出的随机变量的取值集合,信源可以分为离散信源和连续信源两类。对于离散信源
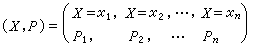
式中X为随机变量,其取值集合为A={x1,x2,…,xn},X 取xi的概率为Pi。例如当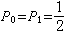 时,二进制数据信源可表示为
时,二进制数据信源可表示为
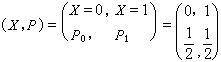
对于连续信源
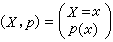
式中随机变量X取值于区间(ɑ,b),对应的概率密度为p(x)。
实际信源是由最基本的单个消息信源组合而成的。离散时,它是由一系列消息串组成的随机序列X1,X2,…,Xj,…, XL来表示。电报、数据、数字等信源均属此类。连续时,它是由连续消息所组成的随机过程X(t)来表示。语声、图像等信源属于这类。对于离散随机序列信源,消息序列X的取值集合为AL,概率分布为PX(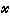 ),记为(X,PX())。
),记为(X,PX())。
离散序列信源又分为无记忆和有记忆两类。当序列信源中的各个消息相互统计独立时,称信源为离散无记忆信源。若同时具有相同的分布,则称信源为离散平稳无记忆信源。例如最简单的(设L=3)脉冲编码信源,当P0=P1=1/2时,
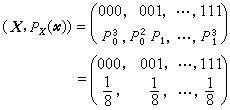
当序列信源中各个消息前后有关联时,称信源为离散有记忆信源。描述它一般比较困难,尤其当记忆长度很大时。但在很多实际问题中仅须考虑有限记忆长度,特别是当信源系列中的任一消息仅与其前面的一个消息有关联,数学上称它为一阶马尔科夫链。在马尔科夫链中,若其转移概率与所在位置无关,则称为齐次马尔科夫链。若同时还满足当转移步数充分大时与起始状态无关,则称它为齐次遍历马尔科夫链。例如数字图像信源常采用这一模型。
连续的随机过程信源,一般很复杂且很难统一描述。但在实际问题中往往可采用以下两类方法。最常见的处理方法是将连续的随机过程信源在一定的条件下转化为离散的随机序列信源;另一种方法则是把连续的随机过程信源按易于分析的已知连续过程信源处理。实际上,绝大多数连续随机过程信源都近似地满足限时(T)、限频(F)的条件。这时,连续的随机过程可以转化为有限项傅里叶级数或抽样函数的随机序列,而抽样函数表达式尤为常用。但这两种方式在一般情况下其转化后的离散随机序列是相关的,即信源是有记忆的。这给进一步分析带来一定的困难。另外一种是将连续随机过程展开成相互线性无关的随机变量序列,这种展开称为卡休宁-勒维展开。由于实现困难,这种展开除具有一定理论价值外,实际上很少被采用。直接按随机过程来处理信源受到分析方法的限制,人们还主要限于研究平稳遍历信源和简单的马尔科夫信源。
上述信源都是单一信源,又称为单用户信源。70年代以来又进一步引入多个相互不独立或相关的信源,称为多用户信源,其目的是研究多用户信源编码,以进一步压缩信源的信息率或达到某些其他目的。但这方面的研究还仅限于离散无记忆信源,这类问题是一个正在探索中的课题。
主要性质
信源输出是随机的,因而它是概率性的。从概率统计观点看,概率分布是信源最基本、最完整的统计特性。对离散无记忆信源,信源消息序列是统计独立的,因此只要知道单个消息的概率分布就能完全决定整个消息序列的联合概率分布。对离散有记忆信源情况就不同了,它必须知道整个消息序列的联合分布,而求有记忆信源的联合分布是很困难的。只是在一些很特殊的情况下,已知分布类型和某些统计参量,如均值、协方差,才能求出分布。最典型的例子是具有有限维的正态分布,其概率分布唯一地决定于均值和协方差。
实际信源分布即使是一维的也往往是未知的,通常采用直方图统计量,以便为实际信源寻找出一个近似的概率分布。在求实际语声、图像分布时,常采用这种方法。
利用概率分布,可以进一步引用信息熵H(X)来描述信源的统计特性。根据信息论可得出以下结论:对离散信源,当信源消息序列独立、等概率分布时,信息熵最大。对连续信源,只有在一定约束条件下才具有最大熵。例如当信号峰值功率受限制时,均匀分布信源的信息熵最大;而当信号平均功率受限制时,正态分布信源的信息熵最大。利用信息熵还可以很方便地描述有记忆信源的统计特性。根据熵的性质,无记忆的单个消息熵大于有记忆的单个消息熵,且记忆越长,单个消息熵就越小。实际信源多数是有记忆的,但是在传送信源消息时往往按无记忆考虑,因此信源存在着压缩的可能性。
实际信源
图像和语声是最常用的两类主要信源。要充分描述一幅活动的立体彩色图像,须用一个四元的随机矢量场X(x,y,z,t),其中x,y,z为空间坐标;t为时间坐标;而X是六维矢量,即表示左、右眼的亮度、色度和饱和度。然而通常的黑白电视信号是对平面图像经过线性扫描而形成。这样,上述四元随机矢量场可简化为一个随机过程X (t)。图像信源的最主要客观统计特性是信源的幅度概率分布、自相关函数或功率谱。关于图像信源的幅度概率分布,虽然人们已经作了大量的统计和分析,但尚未得出比较一致的结论。至于图像的自相关函数,实验证明它大体上遵从负指数型分布。其指数的衰减速度完全取决于图像类型与图像的细节结构。实际上,由于信源的信号处理往往是在频域上进行,这时可以通过傅里叶变换将信源的自相关函数转换为功率谱密度。功率谱密度也可以直接测试。
语声信号一般也可以用一个随机过程X(t)来表示。语声信源的统计特性主要有语声的幅度概率分布、自相关函数、语声平均功率谱以及语声共振峰频率分布等。实验结果表明语声的幅度概率分布可用伽玛(γ)分布或拉普拉斯分布来近似。语声信号的自相关函数,根据实验也可以大致认为属于负指数分布类型,且样点间相关性很强,一般高达0.9以上。语声信号的平均功率谱的测试表明,语声主要能量集中在 1千赫以下。语声的共振峰频率是语声功率谱的主要峰值。这样的峰值并非一个,而且它的值随音调的变化有一定的变动范围。人们对汉语、英语的共振峰分布已获得一定的测试结果。