[拼音]:jisuan fuzaxing lilun
[外文]:computational complexity theory
理论计算机科学的分支学科,使用数学方法对计算中所需的各种资源的耗费作定量的分析,并研究各类问题之间在计算复杂程度上的相互关系和基本性质,是算法分析的理论基础。为了计算一类问题,总要耗费一定的时间以及存储空间等资源。资源耗费的多少决定于被计算问题的大小,是问题大小的函数,称为问题对该资源需求的复杂度。对复杂度函数增长的阶作分析,探讨它们对于不同的计算模型在一定意义下的无关性,根据复杂度的阶对被计算的问题分类,研究各种不同资源耗费之间的关系,对一些基本问题的资源耗费情况的上、下界作估计等,构成计算复杂性理论的主要研究内容。
数理逻辑和数学本身的发展,在20世纪30年代建立了可计算性理论。40年代以后,随着计算机科学技术的发展,人们不仅需要研究理论上的、原则上的可计算性,还要研究现实的可计算性,即研究计算一个问题类需要多少时间,多少存储空间;研究哪些问题是现实可计算的,哪些问题虽然原则上可计算,但由于计算的量太大而实际上无法计算等。这就使得计算复杂性理论作为理论计算机科学的一个分支而发展起来。
计算模型
为了对计算作深入的研究,需要定义一些抽象的机器。30年代所定义的简单图灵机、递归函数等都是计算的模型。但当时都只考虑到理论上的可计算性而没有考虑计算的复杂性。因此,为了度量计算的复杂性,70年代前后又提出多带图灵机模型、随机存取机器模型等串行计算模型和向量机器模型等并行计算模型。
资源
资源的确切定义决定于计算的模型。例如,对于多带的图灵机,就有串行时间、空间、巡回等资源(见公理复杂性理论)。一般说来,各种模型的主要资源有并行时间、空间和串行时间三种。
并行时间和巡回
并行时间一般指并行计算模型计算时所需步数,例如向量机的自始至终执行指令的总条数。但对串行模型也可以定义一种称为巡回的资源。可以证明它相当于并行时间。对于多带图灵机,它是工作带头部改变方向的次数。一般地说,巡回是周相的总数,而周相则是串行模型工作中的一个阶段,在此阶段中被计算出来而记录在工作空间上的信息,在此阶段内不再被读到。
空间
在计算过程中需要记录下来以备后用的最大中间信息量。对于多带图灵机,是计算过程中用过的工作带上的方格数。
串行时间
计算过程中原始运算的总量。因此,对于串行模型而言,它代表计算自始至终的总步数。对于并行模型而言,每一步可以同时作许多个原始的运算,自始至终各步的原始运算数目的总和就是串行时间。
最坏情况复杂度和平均情况复杂度
在定义任何一种资源时,例如定义时间耗费时,时间是输入字符串w的函数,记为t(w)。对于所有长度等于n的字w,t(w)中必有最大的一个(可能是无穷大),这个值只与n有关,可以记为T(n),称为最坏情况复杂度。如果考虑对所有长度等于n的字,取t(w)的平均值,就得到平均复杂度。它当然不超过最坏情况复杂度。
相似性原理
对图灵论题的进一步研究,可断言各计算模型在计算能力上的大致等价性。也就是说,对于同一类计算问题而言,各理想的计算模型使用本质上同样多的并行时间、本质上同样多的空间和本质上同样多的串行时间,三者同时成立。所谓本质上同样多是指多项式相关联。
以多带图灵机和向量机器为例,可以证明下面的相似性定理:设n是输入字符串的长度,它代表问题的大小。对于任何一个多带图灵机,设它的巡回为R(n),空间为S(n),串行时间为T(n),则一定有一个向量机器来模拟它,使得存在一个多项式p,向量机器的并行时间R1(n),空间S1(n)和串行时间T1(n)满足
R1(n)≤p(R(n))
S1(n)≤p(S(n))
T1(n)≤p(T(n))
在以上结论中把多带图灵机和向量机器的位置对调一下也成立。这说明在多项式相关联意义下,这两个模型没有本质的区别。因此,巡回是串行模型的虚拟并行时间。
计算的类型
这里只考虑判定问题或是非问题。机器状态转移和接受输入的方式称为计算的类型。在普通计算中,机器状态只依赖于时间和输入,是完全确定的。每一步都由前一步所达到的状态惟一确定。如果机器最后进入一个接受状态,就认为机器接受了输入。这种计算称为确定型的,计算的过程可以用一条链来表示(图1)。确定型是最简单的一种计算类型。

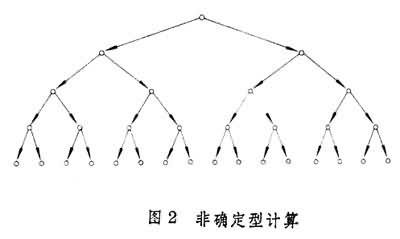
但有时机器在某一时刻可以有若干种选择,进入若干不同状态,而在新的情况下又有若干不同选择等。这时计算过程可用一棵树表示(图2)。若规定只要有一条路从树根通向一个接受的顶点,就认为机器接受了输入字符串,这种接受方式就叫作非确定型的(见非确定性)。此时,树高被看作是非确定计算所需的时间。
随机型计算的定义有许多种。较弱的一种定义为:从计算树的根往下走,每到一个岔路口就扔一枚钱币以决定去向。如果用这种方式碰到一个接受状态的概率大于1/2,就接受输入字w。较强的一种定义为:如果输入应该被拒绝则机器一定拒绝,如果输入应该被接受则机器接受的概率大于或等于 1/2。或者说,若输入该被拒绝,机器是不会犯错误的;否则机器犯错误的可能性不超过一半。这种算法又称为概率算法。
R.索罗威和V.史托拉森找到一个多项式时间的随机型素数判定算法。若被判定的数m的确是一个素数,则算法一定会回答是素数。若m不是素数,则算法回答是素数的可能性小于1/2。可以不断对m重复这一算法,而且每次的结果是独立的。例如重复100次,若每次回答都是素数则可断言它是素数,只要有一次回答不是素数则可以肯定它不是素数。这样,犯错误的可能性将小于2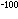 。由于尚未找到确定型多项式时间素数判定算法,这类概率算法就具有很重要的意义。最早的这样一个算法由E.R.伯勒嵌普给出。他找到一个多项式时间的概率算法,去分解p个元素的域GF(p)上的一个多项式。
。由于尚未找到确定型多项式时间素数判定算法,这类概率算法就具有很重要的意义。最早的这样一个算法由E.R.伯勒嵌普给出。他找到一个多项式时间的概率算法,去分解p个元素的域GF(p)上的一个多项式。
计算理论中有重要意义的计算类型还有交错型等。
相似性原理和相似性定理不仅对确定型计算成立,而且对非确定型、交错型、随机型等各种计算类型都是成立的。
复杂性类
根据识别时资源耗费的复杂程度而对形式语言所作的分类。在多项式时间内用确定型机器可识别的语言可归入一类,记为P。把那些用非确定型机器在多项式的串行时间内可识别的语言归入一类,记为NP(见NP完全性)。在这种条件下无需说明采用什么计算模型,因为根据相似性原理,不论采用何种模型,P和NP的意义是不变的。
N.皮彭格提出P的一个重要子类称为NC,它由所有同时可在多项式的空间和对数多项式的并行时间内可计算的函数组成。如果说P代表现实可计算的问题,那么NC即代表其中用多项式处理机在对数多项式时间内计算的问题。整数的加减乘除运算、整序、图联通性、矩阵的乘法、除法、行列式、多项式的最大公因子、上下文无关语言识别、找图的最小张开树等问题都属于NC。
与之对偶的另一个子类由所有同时可在多项式的并行时间和对数多项式的空间内计算的函数所组成,称为SC。
在确定型多项式空间中可判定的语言类记为PSPACE。就已有的计算模型而言,在确定型多项式并行时间中可判定的语言类恰为PSPACE。
当然,还可以考虑概率型的机器在对数多项式并行时间和多项式空间中可识别的语言类等。根据相似性原理,这些类的定义都是独立于计算模型的。
归约和完全性
研究复杂性类和其间关系的方法。在数学中,常常把一类问题的计算归结为另一类问题的计算。例如,利用公式
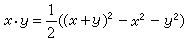
可把乘法归约为平方、加减法和用2 除。如果平方、加减法和用2除能很快算出来,乘法也就可以很快地算出来。
设有两个语言L1、L2和一个简单易行的变换T,如果一个字X属于L1,当且仅当变换以后的字T(x)属于L2,那么就说变换T 把L1归约成L2。因为,若要判定某个字X 是否属于L1,只要用T 变换一下,然后去判断T(x)是否属于L2就行了。为了使得归约是有实际意义的,就要求T是一个容易实现的变换。例如,可在对数空间中实现。这时就说L1在对数空间中归约为L2。
设C是一个复杂性类,L是任一语言。如果 C中任何语言都可以在对数空间中归约为L,就说C可在对数空间中归约为L。或者说,L属于C 难。其直观意义为:若L可以容易地计算出来,则C 中任何问题均可以容易地计算出来。反之,若C 中有难于识别的问题,则L的识别肯定不会更容易(故称为C 难)。进一步说,如果L属于C 难,而且本身也属于C,就说L在C 中是完全的。意意是:C 中任何语言可以很快识别,当且仅当人可以很快识别。
归约和完全性是复杂性理论中重要的研究方法。第一个NP完全性问题由S.A.库克在1971年提出,R.卡尔普等人解决了一系列基本的NP完全性问题。
复杂度的上界和下界
用以估计问题所需某资源的复杂程度的界限函数。如果找到解某问题的算法,其资源的复杂度为u(n),则u(n)是问题本身复杂度的一个上界。如果对任何算法,其复杂度都必需大于l(n),则l(n)是问题复杂度的一个下界。
对各类具体问题的复杂度的上、下界的研究,一般说来属于算法分析的范围。但有时也把某些基本问题的上、下界的研究归入复杂性理论。
n维的快速傅里叶变换需要O(n logn )次算术运算;n位的乘法在多带图灵机上需时O(n log n log log n);n阶矩阵乘法只需要4.7n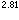 次算术运算,判定一个n位数是否为素数需时O(
次算术运算,判定一个n位数是否为素数需时O(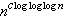 );在出度限定情形下的图同构的判定,存在多项式时间算法。
);在出度限定情形下的图同构的判定,存在多项式时间算法。
下界的结果多借助于对角线方法得出,最典型的是关于复杂性谱系的一系列结果。带有平方的正规表达式的等价问题的判定需要指数的空间。例如,不难证明,为了把n个数排序,比较的次数至少正比于nlogn。又如n个点的多项式的插值问题,若只许用算术运算,则至少需要nlogn次乘法。关于两个资源乘积的下界,为了识别n 位的完全平方数,在一个离线的图灵机上,时间和空间的乘积至少正比于n2。为了对n 个大小从1到n2之间的数排序,时间和空间的乘积至少正比于n2/logn。为了识别任何非正规的语言,多带图灵机的工作空间和工作带巡回数的乘积的阶不能小于n。
从发展趋势来看,计算复杂性理论将深入到各个数学分支中去。计算机科学的发展,特别是新一代计算机系统和人工智能的研究,又会给计算复杂性理论提出许多新的课题。计算复杂性理论、描述复杂性理论、信息论、数理逻辑等学科将有可能更紧密结合,得到有关信息加工或信息活动的一些深刻结论。
- 参考书目
- A.V. Aho, J.E.Hopcroft & J.D.Ullman,The Design and Analysis of Computer Algorithms, Addison-Wesley,Reading,Mass.,1974.
- J. E. Hopcroft, & J.D. Ullman, Introduction to Automata Theory,Languages and Computation,Addison-Wesley,Reading,Mass.,1979.